小组两项研究成果被IEEE/ACM会议ASE 2025直接接收
IEEE/ACM International Conference on Automated Software Engineering (ASE) 是自动化软件工程的顶级学术会议,每年汇集来自学术界和工业界的大量研究人员和从业人员,重点关注自动化大型软件系统的分析、设计、实施、测试和维护的基础、技术和工具。2025年,ASE共直接接收文章113篇,Marjoy revision 140篇,直接接收率为9.5%(113/1190)。本次清华大学软件系统安全保障小组共有2项研究成果被ASE2025直接接收。
第一项成果是 “DualFuzz: Detecting Vulnerability in Wi-Fi NICs through Dual-Directional Fuzzing” 。该工作面向Wi-Fi网卡(NICs)中的安全漏洞,提出了一套自动化检测框架 DualFuzz,在Intel、Realtek等8个主流Wi-Fi网卡中挖掘出 21 个未知缺陷,具有广泛的工程应用前景和实践价值。本工作由博士生陈元亮等人参与完成,清华大学博士后马福辰和清华大学姜宇副教授等人共同指导。
研究成果概要:
Wi-Fi 网络接口卡(NIC)是实现各种设备无线连接的关键组件。保障其安全性至关重要,因为一旦存在漏洞,可能会危及整个网络的安全。模糊测试是一种有前景的技术,能够有效发现此类缺陷。然而,现有的 Wi-Fi 模糊测试工具,如下图所示,通常只针对发送或接收进行测试,忽视了两者之间的交互,导致测试效率低下。
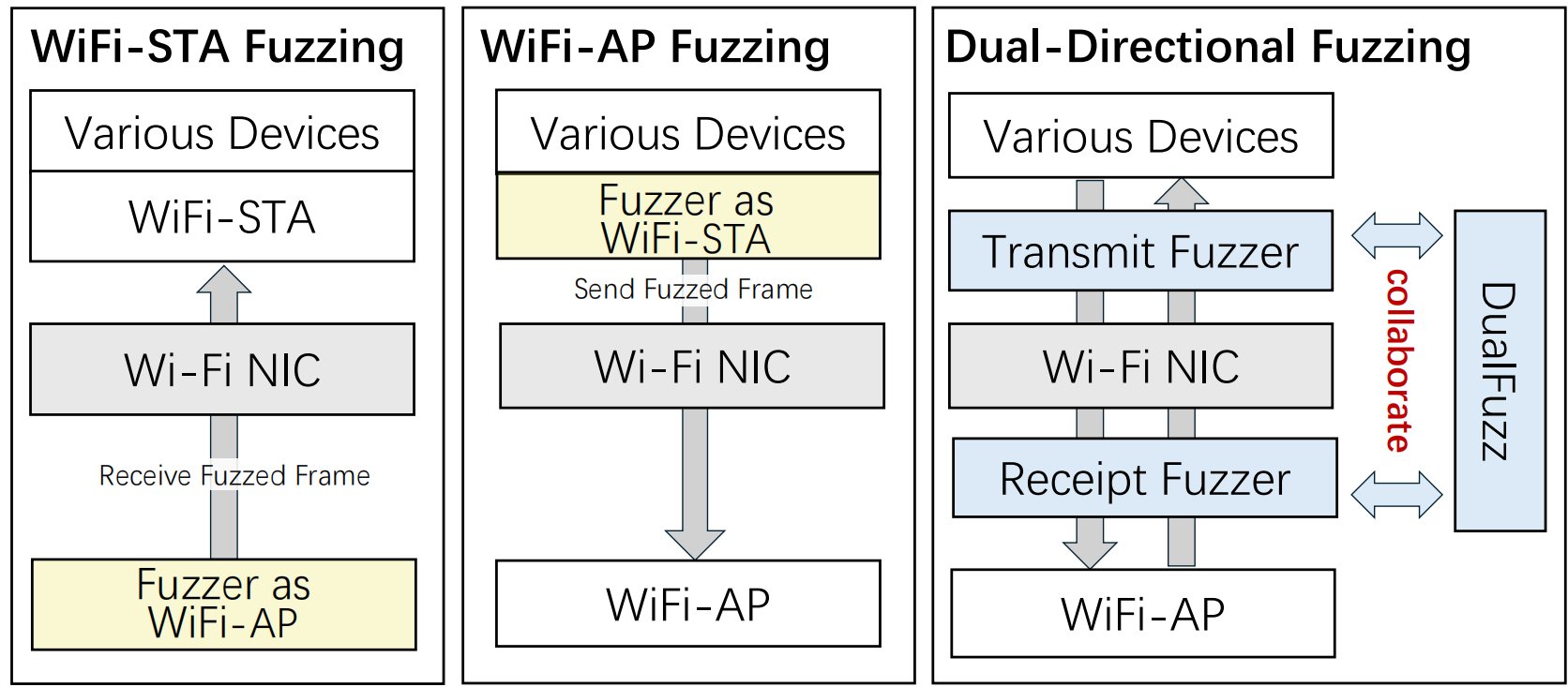
因此,本文提出了 DualFuzz,一个面向双向交互的模糊测试框架,旨在同时测试 Wi-Fi 网卡中的发送与接收过程。首先,DualFuzz 能自动识别 Wi-Fi 网卡中的交互行为,并构建一个 发送-接收模型(TRModel),用于刻画影响这些交互的 Wi-Fi 帧。基于该模型,DualFuzz 采用 延迟引导的模糊测试策略,以高效协同地探索发送与接收过程中的交互逻辑。最后,我们设计了 活性检测器和等价性检测器,可实时监测 Wi-Fi 网卡的运行状态,及时识别异常行为并挖掘潜在漏洞。
DualFuzz的主要流程如下图所示,包含三个重要组件:TRModel, Latency Guided Fuzzer 以及 bug检测器。
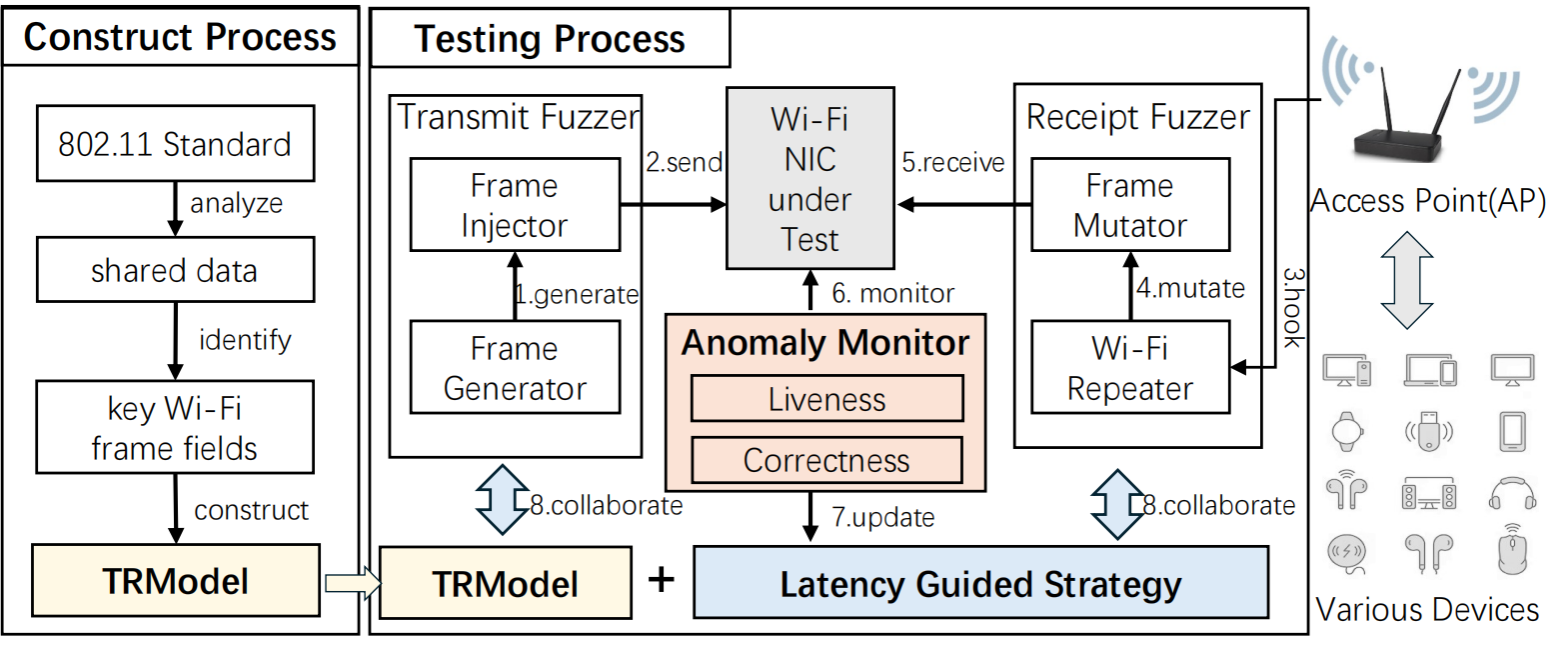
- 收发包模型TRModel: 考虑到所有 Wi-Fi 网卡的实现均遵循 IEEE 802.11 标准,DualFuzz 通过对该标准进行静态分析,自动提取发送-接收交互逻辑并构建 TRModel,过程包括四个步骤:1. 筛选 IEEE 802.11 标准中描述关键操作行为的章节;2. 提取共享数据并分析 Wi-Fi 帧类型;3. 对每个字段执行静态语义分析;4. 对 TRModel 进行映射与精化处理。
- 延迟引导的模糊测试器:由于 DualFuzz 采用黑盒设计,它无法访问某些 Wi-Fi 网卡的运行时内部数据(例如许多模糊测试工具常用的代码覆盖率)。同时,若随机生成发送-接收帧组合,测试效率会较低。为了高效协调这两个输入维度(即发送与接收)的探索,DualFuzz 采用了一个关键启发式策略:帧的处理延迟越长,越有可能触发 Wi-Fi 网卡中更深层次的交互逻辑,从而越有可能暴露隐藏的漏洞。
- 网卡异常检测器:为了确保通用性,DualFuzz 被设计为一个黑盒测试工具。因此,系统实现了 异常监测器(Anomaly Monitor),用于在不依赖源码或专有接口的情况下,追踪被测 Wi-Fi 网卡的运行时行为。模块包含两类主要的漏洞检测器:第一类是 活性检测器(liveness detector),用于判断 Wi-Fi 网卡是否由于崩溃或连接异常等问题而离线或失去正常功能;第二类是 等价性检测器(equivalence detector),用于识别注入帧与实际发送帧之间的不一致,从而揭示网卡内部潜在的帧处理错误。
第二项成果是 “ARG: Testing Query Rewriters via Abstract Rule Guided Fuzzing” 。该工作针对查询改写器中潜在的缺陷进行深入分析,提出了测试工具ARG,旨在检测查询改写器中潜在的语义改写错误和崩溃问题。ARG利用SQL语句改写前后的语法树结构信息,构建抽象规则来拟合查询改写器中的等价规则组合情况,并通过抽象规则反馈指导测试用例的生成,从而激活改写器内部更多的改写逻辑。实验结果表明,ARG在4个查询改写器中检测到了38个缺陷,并取得了76%-1017%的规则覆盖数量提升。本工作由北航副教授李大伟,北航博士生郭宇潇、刘启帆等人参与完成,北航梁杰副教授和清华大学姜宇副教授等人共同指导。
研究成果概要:
查询重写器(Query Rewriter)是数据库管理系统(DBMS)中提升查询效率的核心组件,它能将用户输入的查询语句转换为功能相同但执行效率更高的形式。然而,查询重写器逻辑复杂,其实现过程极易引入缺陷,可能导致系统崩溃、返回错误结果或产生语义偏差,进而影响数据的准确性与系统的稳定性。现有的通用数据库测试工具并非专为测试查询重写器设计,因此难以系统性地覆盖复杂的重写逻辑,常常会遗漏深层次的关键漏洞。
为此,该工作提出了ARG,一个专用于测试查询重写器的模糊测试框架。ARG的核心思想是,通过分析原始查询与重写后查询之间的语法树结构差异,自动学习并构建出抽象重写规则,再利用这些规则作为反馈,指导后续测试用例的生成,从而更精准、更高效地触发重写器的内部逻辑,以发现潜在的错误。
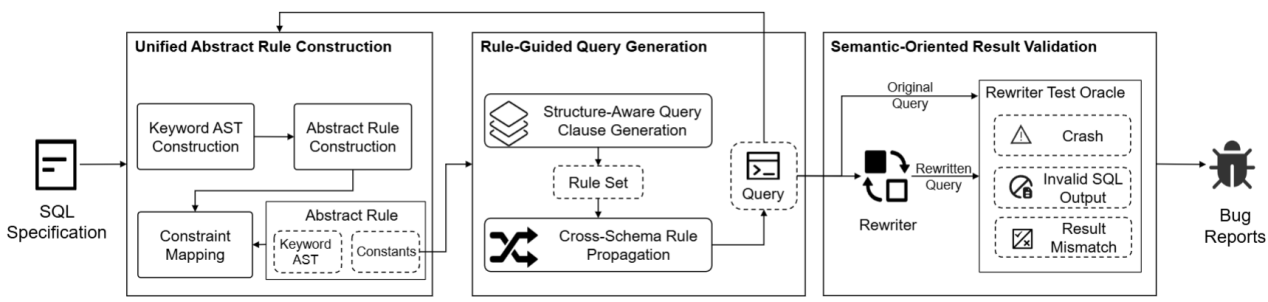
ARG 的主要流程包含三个核心组件:
- 统一抽象规则构建:ARG通过解析原始查询和重写器输出的新查询,构建两者的抽象语法树。通过对比这两棵树的结构差异,结合相关的数据库表结构信息,ARG能够自动提炼并形成一个能统一表示重写行为的抽象规则。
- 规则指导的查询生成:ARG利用提取的抽象规则作为反馈,动态地指导SQL查询生成器。系统会优先探索那些尚未被触发过的重写模式,生成结构更多样化、更具针对性的查询语句,从而避免随机测试的盲目性,系统性地覆盖更广泛、更复杂的重写逻辑。
- 面向语义的结果验证:为了精准地检测漏洞,ARG设计了一套验证机制,可持续监控并识别三类主要的缺陷:第一类是重写器崩溃,具体表现为重写器在处理某个查询时发生程序崩溃;第二类是无效SQL输出,具体表现为重写后的查询包含语法或语义错误,导致数据库无法执行;第三类是语义偏差,具体表现为重写前后的查询虽然都能成功执行,但返回的结果集不一致,这表明重写逻辑存在错误,破坏了语义等价性。