小组两项研究成果被ACM会议SIGMOD 2026接收
国际数据管理会议SIGMOD(ACM SIGMOD International Conference on Management of Data),是数据库和数据管理领域最具权威性的三大会议之一,与其他会议VLDB、ICDE齐名,并被中国计算机学会(CCF)推荐为数据库领域的A类国际会议。本次清华大学软件系统安全保障小组共有2项研究成果被SIGMOD 2026接收。
第一项成果是“Finding Missed Optimizations in DBMSs through Unbalanced Short-Circuit Query Construction”。该工作针对数据库管理系统(DBMS)中的遗漏性能优化,提出了一种基于不平衡短路查询构造的数据库性能缺陷检测方法SCor,在Oracel、PostgreSQL、MySQL、MariaDB、SQLite等11个流行的DBMSs中发现了153个未知缺陷,收到了MariaDB首席科学家Daniel Black的感谢信,以及PostgreSQL、SQLite、CockroachDB等众多数据库厂商开发者的积极反馈。本工作由南昌大学赖锦辉博士、清华大学张弛博士后、北京航空航天大学梁杰副教授等人共同完成,清华大学姜宇副教授和南昌大学徐子晨教授等人共同指导。
研究成果概要:
DBMS是现代数据密集型应用的核心基石,其执行性能直接决定了系统的响应效率与终端用户体验。为提升查询处理效率,现有DBMS针对SQL查询设计并实现了大量复杂的优化机制。然而,受限于SQL查询语义与DBMS系统架构的高度复杂性,实际系统在实现过程中仍普遍存在潜在优化机会遗漏的问题,进而引发执行性能下降、资源利用率偏低、用户体验受损等一系列问题。由于查询语义、优化器决策与实际执行行为之间存在复杂的耦合关系,精准识别这些被遗漏的优化点极具挑战性。现有检测方法虽能j检测因优化策略不完善所引发的性能问题,但鲜有工作能够有效揭示完全缺失的优化逻辑,导致大量潜在的性能提升空间未被挖掘。
针对上述问题,本文提出一种基于不平衡短路查询构造的数据库性能缺陷检测方法SCor。SCor的核心思想在于:许多查询的结果无需完整执行即可确定,而DBMS仍会执行完整查询流程,进而暴露出潜在的优化缺失问题。例如,对于表达式FALSE AND highCostExpr,DBMS本可直接判定结果为假,无需执行高代价子表达式 highCostExpr。SCor基于这一思路,通过构造不平衡短路查询实现性能检测,即查询结果仅通过低代价部分便可确定。若DBMS仍执行包含高代价操作的完整查询,则说明存在未实现的短路优化。由于短路模式在SQL查询中普遍存在,且可灵活嵌入各类查询结构,SCor能够系统性地应用于广泛场景,有效暴露多种类型的优化缺失问题。本文在11款主流DBMS上开展了实验评估,结果表明:SCor共发现153个由优化缺失导致的性能缺陷,其中包括Oracle数据库2个缺陷、PostgreSQL数据库3个缺陷。
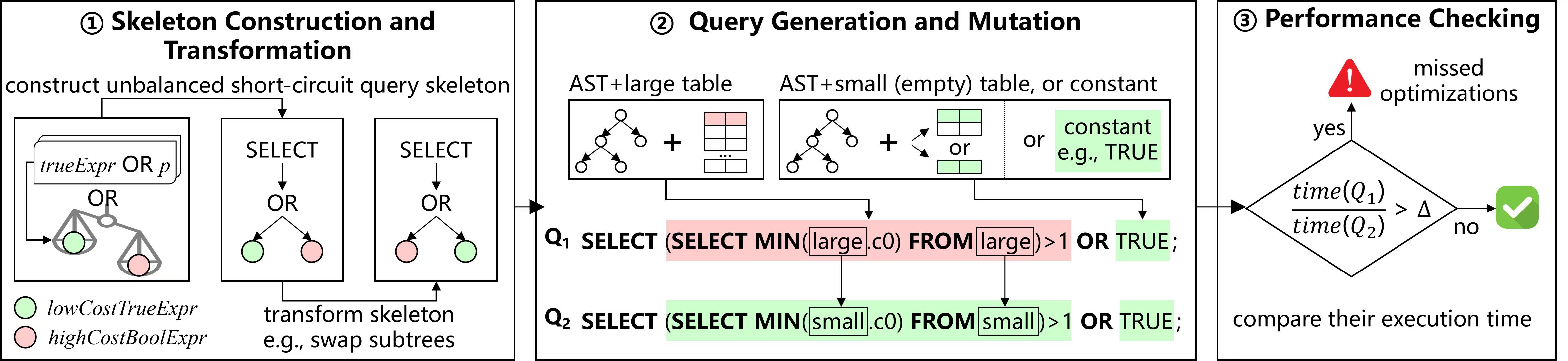
SCor的主要流程包含三个核心环节,如上图所示:
(1)短路查询骨架构造与结构变换:SCor依托DBMS中广泛应用的10类短路执行模式(AND-OR、CASE-WHEN、CTAS、LIMIT、COALESCE、SEMI-JOIN等),构建非平衡短路查询骨架。该骨架完整保留SQL核心操作关键字,将表名、字段、常量等具体元素统一替换为标准化占位符,并按执行代价划分为低成本占位符与高成本占位符两类;同时通过子树交换、增加子树等变换策略,丰富查询骨架的结构多样性,覆盖更多短路执行场景。 (2)非平衡短路查询生成与基准变异:SCor基于选择的查询骨架完成实例化,生成可执行SQL查询:低成本占位符填充常量、空表等低执行代价元素,高成本占位符赋予大表、复杂衍生表达式等高执行代价元素,最终构建具备短路特性的非平衡目标查询Q1。在理想优化场景下,Q1中的高成本表达式仅需解析器完成语法解析,无需执行器实际运算。随后对Q1进行基准变异:将查询中所有大表引用,替换为同Schema、不同数据量的小表或空表,生成无高成本执行压力的基准查询Q2。 (3)数据库性能缺陷识别:分别执行目标查询Q1与基准查询Q2,精准对比两者的实际执行耗时。在DBMS完成短路优化的前提下,Q1因满足短路执行条件,执行耗时应与Q2基本持平;若两者耗时出现显著差异,则证明DBMS未识别并利用潜在短路优化机会,存在明确的性能优化缺陷。分别执行目标查询Q1与基准查询Q2,精准对比两者的实际执行耗时。在DBMS完成短路优化的前提下,Q1因满足短路执行条件,执行耗时应与Q2基本持平;若两者耗时出现显著差异,则证明DBMS未识别并利用潜在短路优化机会,存在明确的性能优化缺陷。
第二项成果是“EPSC: Testing Database Management Systems via Equivalent Prepared Statement Construction”。该工作面向数据库管理系统中存在的逻辑缺陷,提出了自动化检测方法EPSC,在PostgreSQL、MySQL、SQLite3等主流数据库管理系统中检测出52个此前未知的个缺陷,其中28个为逻辑缺陷,具有广泛的工程应用前景和实践价值。本工作由博士后张弛等人参与完成,清华大学姜宇副教授指导。
研究成果概要:
数据库管理系统(DBMS)是保障数据存储、管理与查询的核心基础设施。由于其代码规模庞大及优化复杂,其中存在大量缺陷,逻辑缺陷是常见缺陷类型之一。逻辑缺陷(Logic Bug)是指导致数据库在执行特定语句时产生错误结果的漏洞。由于这类缺陷触发时缺乏明显的系统异常特征(如崩溃或报错),开发者和使用者往往难以察觉。目前,蜕变测试是检测逻辑缺陷的主流方法之一,其核心在于基于现有测试用例构建后续用例,并通过验证两者是否符合预期的蜕变关系来捕捉缺陷。现有方法主要针对数据查询语言(DQL,如SELECT)中存在的逻辑缺陷,从语义等价、配置等价的角度构造测试预言,而针对数据操纵语言(DML,如INSERT、UPDATE、DELETE)和预编译语句中存在的逻辑缺陷仍面临挑战。
因此,本文提出EPSC(Equivalent Prepared Statement Construction),一个基于预编译语句的逻辑缺陷黑盒测试方法,同时检测数据操纵语言、数据查询语言以及预编译语句中存在的逻辑缺陷。预编译语句是数据库管理系统中提升重复执行语句性能以及防止SQL注入攻击的主要手段,其支持将常量作为SQL语句的参数,首先不带参数进行语句的编译及优化,然后绑定参数执行。在优化过程中,由于参数未知,因此大量优化策略如短路优化、常量折叠等无法被应用,导致其查询计划与执行路径与普通语句存在显著差异。EPSC 的核心思想是利用这种差异构建测试预言:等价的普通语句与预编译语句应当产生完全一致的结果,任何输出偏差均指向潜在的逻辑缺陷。由于 DML 与 DQL 均支持预编译模式,EPSC 实现了对这两类语句缺陷的全面覆盖。
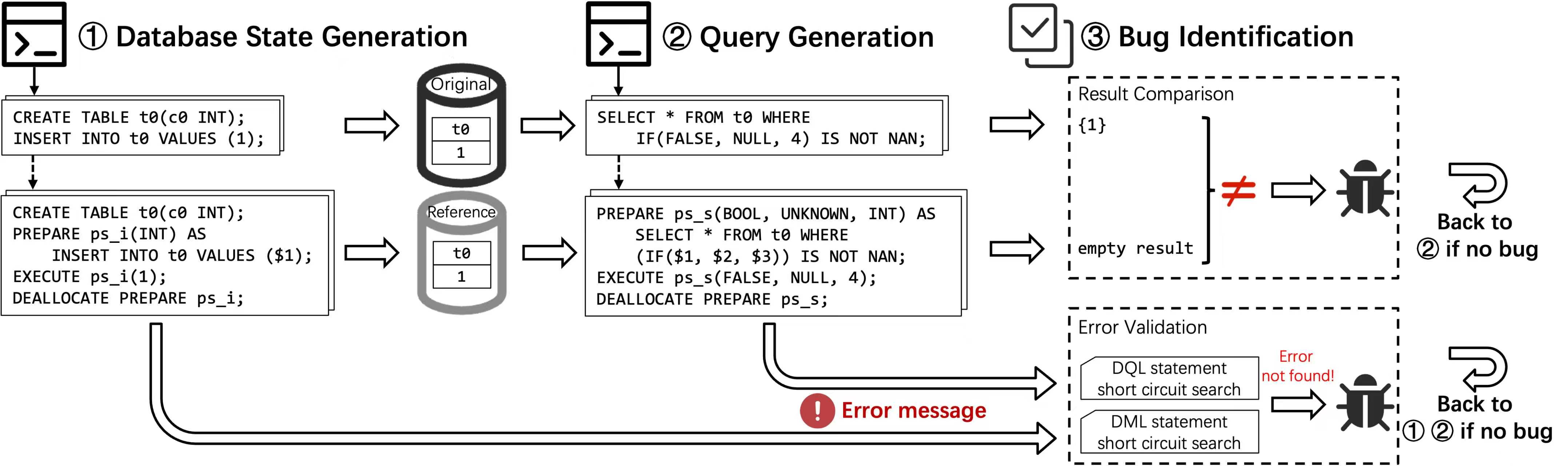
EPSC主要包含数据库状态构建、查询生成、缺陷识别三个步骤。测试过程中,EPSC 维护“原始”与“参考”两个数据库。在步骤一中,系统通过数据定义语言(DDL)创建表、视图与索引,并生成 DML 语句插入数据;此时,在原始数据库中执行普通 SQL,而在参考数据库上则将 DML 转化为预编译语句执行。在步骤二中,系统生成多种查询请求,同样在两个数据库上分别以普通和预编译模式运行。步骤三通过对比两者的结果识别缺陷:不一致性可能源于查询语句中的逻辑缺陷,也可能由于 DML 执行阶段触发的逻辑缺陷导致的状态不一致。此外,针对测试用例中引入的语法或语义错误(如除零异常),普通语句常因短路优化而跳过错误,而预编译语句则会触发异常,从而产生误报。为解决此问题,EPSC 引入了错误验证机制,通过深度优先遍历提取并强制执行各级子表达式;若能复现相同错误,则归因为优化差异导致的正常行为,否则判定为非预期的错误或逻辑缺陷。 基于提出的方法EPSC在七个广泛使用的数据库管理系统中检测出52个缺陷,缺陷分布于数据操纵语言、数据查询语言、预编译语句中。此外,EPSC所引入的错误验证机制消除了99%以上的误报,并成功发现多个本应触发错误但成功执行并返回结果的逻辑缺陷。